
Qué es UTF-8 y por qué es la mejor codificación de caracteres
Este post que comienzas a leer es el resultado de una codificación de caracteres. Sí, lo cierto es que cada letra escrita, en el resto de la web de Raiola Networks y en cualquier otra web que quieras visitar, también ha sido interpretada por un método de codificación para que puedas visualizarla sin ningún problema, independientemente del idioma o el dispositivo que estés usando.
Este método de codificación del que hablamos es UTF-8, del que te hablaré en las próximas líneas. Está mucho más presente de lo que creías y veremos cuál es su importancia a nivel de desarrollo web y por qué es la mejor codificación de caracteres.
¡Empezamos!
- ¿Qué es UTF-8 y para qué sirve?
- UTF-8 y el estándar Unicode: la clave para la compatibilidad global
- Diferencias entre UTF-8, UTF-16 y UTF-32
- ¿Por qué UTF-8 es el estándar más usado en la web?
- Cómo funciona la codificación UTF-8
- Representación de caracteres en UTF-8
- Compatibilidad de UTF-8 con navegadores y sistemas operativos
- Cómo convertir archivos y texto a UTF-8
- Convertir archivos a UTF-8 paso a paso
- ¿Cómo saber si un archivo está en UTF-8?
- Caracteres extraños y errores de codificación
- Por qué UTF-8 es el mejor estándar de codificación

¿Qué es UTF-8 y para qué sirve?
Cualquier dispositivo que sea capaz de mostrar texto está regido por una serie de parámetros que le indican cómo debe interpretar cada caracter ingresado por los usuarios para que se pueda visualizar en pantalla. UTF-8 es el método de codificación que define dichos parámetros, convirtiéndose en el estándar en la mayoría de los casos.
Cuando hablamos de caracteres englobamos letras, signos de puntuación, símbolos para matemáticas o incluso notas musicales. UTF-8 es capaz de mostrarlos todos y por ese motivo se usa para la codificación de páginas web y correos electrónicos.
UTF-8 y el estándar Unicode: la clave para la compatibilidad global
Originalmente, los primeros equipos informáticos usaban ASCII (American Standard Code for Information Interchange) un sistema de 8 bits que permitía transformar los 0 y 1 de un código binario hacia un formato de texto, representando hasta 128 caracteres diferentes. Como sabrás, existen muchos más caracteres, sobre todo si tenemos en cuenta otros idiomas que usan los suyos propios, como pueden ser el árabe, el griego, el ruso, el japonés y muchos más. Es por ese motivo que ASCII se quedó corto.
A raíz de esto hubo un intento de hacer variables de ASCII para cada alfabeto, algo que se convertía en un caos. Es aquí donde entra en juego UNICODE que logró unificar a todos ellos en un único estándar de codificación.
A diferencia de ASCII, UNICODE funcionó desde un inicio como un sistema de 16 bits, logrando así representar hasta 60.000 caracteres. A medida que iba necesitando más caracteres fue ampliando y, a día de hoy, funciona con hasta 32 bits, ofreciendo la posibilidad de mostrar más de 135.000 caracteres distintos.
Obviamente, esto tiene un inconveniente: el espacio necesario para mostrar cada caracter, casi cuatro veces de lo que requería ASCII. Para tratar de minimizar lo máximo posible el espacio necesario, se buscó una manera de generar espacios flexibles. Por decirlo de alguna manera, adaptar el espacio de cada caracter al mínimo requerido.
Esta norma de ajustar el espacio al mínimo necesario se denominó UTF (Unicode Transformation Format). De este método de codificación existen tres tipos: UTF-8, UTF-16 y UTF-32 de los que hablaremos a continuación.
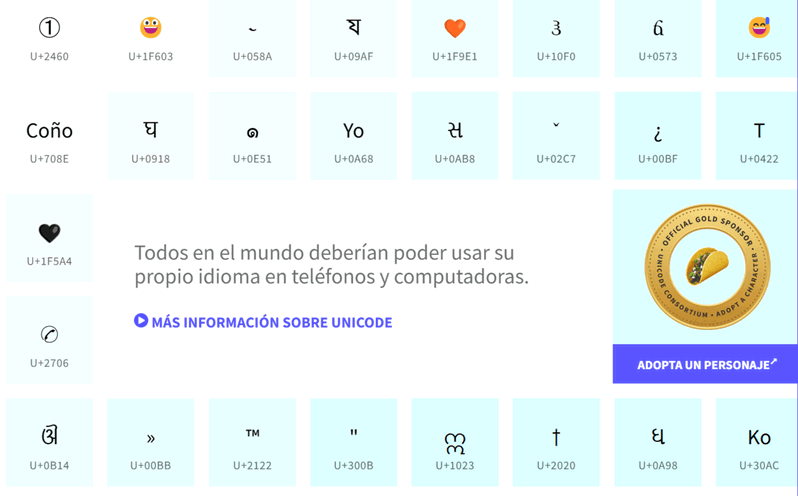
Diferencias entre UTF-8, UTF-16 y UTF-32
La principal diferencia que existe entre los tipos de UTF se basa en el número de bits requeridos. Veámoslo en detalle.
- UTF-8: es el más flexible de todos. Para funcionar necesita al menos 8 bits y su uso está destinado a símbolos de longitud variable. Estos símbolos van desde los más simples como letras de nuestro alfabeto o símbolos de puntuación, que ocupan 7 bits; luego estarían otros alfabetos como el hebreo o el árabe, que ocupan 16 bits; los caracteres de los alfabetos restantes, que ocupan 24 bits; y por último aquellos más complejos como símbolos de geometría, física o incluso la mayoría de los emojis que tanto usamos en redes sociales.
- UTF-16: como su nombre indica, UTF-16 utiliza 16 bits, lo cual lo hace ideal para alfabetos más complejos, como suelen ser los asiáticos como el chino o el japonés. En cambio, para alfabetos occidentales no es la mejor opción porque requiere el doble de espacio que UTF-8. Es muy usado en aplicaciones y programas informáticos.
- UTF-32: Es el único UTF de longitud fija, necesita mucho espacio en comparación con el resto de métodos de codificación. Es útil cuando prevalece un buen procesamiento sin importar el espacio.
¿Por qué UTF-8 es el estándar más usado en la web?
La razón principal de que UTF-8 se haya situado como el estándar más usado en web es por su compatibilidad con ASCII. Cubre los 128 primeros caracteres y, por lo tanto, cualquier texto en ASCII es completamente idéntico en UTF-8. Esto permitió que muchos sistemas con ASCII no tuvieran que adaptarse.
Además, es UTF-8 es compatible con todos los caracteres de UNICODE, lo que lo hace muy cómodo cuando son necesarias traducciones. Todo ello bajo una eficiencia importante de espacio, siendo la elección más lógica como estándar universal para desarrollo web.
Cómo funciona la codificación UTF-8
A diferencia de ASCII, UTF-8 necesita una codificación más especial. Para entender mejor cómo funciona esta codificación UTF-8, usaremos un ejemplo.
U+XXXX
En este formato, la "U+" significa que se trata de un caracter representado en UNICODE, mientras que el código que le sigue, está representado en código hexadecimal, el cual especifica el número de bits empleado en cada caso.
Esta representación la conocemos como "Punto de código" y debe ser transformada mediante UTF-8 a binario para que el dispositivo lo pueda entender.
Por ejemplo, la letra "C" tendría el punto de código: "U+0043". El número hexadecimal "0043" entra dentro del rango de los 24 bits, ya que cada dígito puede representar 4 bits. Puesto que UTF-8 es compatible con ASCII para este rango de caracteres, la letra "C" en UTF-8 se representa igual que en ASCII.
Pues bien, en binario sería: "0000000001000011" que es lo que necesitaría un dispositivo para funcionar y mostrar correctamente la letra "C". De esta manera funciona la codificación UTF-8.
Representación de caracteres en UTF-8
Si necesitas consultar cuál es la codificación exacta de cualquier caracter en UTF-8 existen multitud de herramientas online que te lo facilitan. Sin ir más lejos, puedes verlo en esta página que recoge una tabla con todos los caracteres UNICODE. Algo tal que así, que como ves, sigue el formato anteriormente explicado.

Compatibilidad de UTF-8 con navegadores y sistemas operativos
La compatibilidad es algo de lo que podrías despreocuparte cuando hablamos de UTF-8. Al convertirse en un estándar universal, este método de codificación es compatible con la mayoría de los navegadores y sistemas operativos más utilizados. Quizá solo en algunos casos muy puntuales no lo sea, como en versiones antiguas de sistemas operativos, como Windows 95, o editores de texto y correos obsoletos.
Navegadores compatibles
- Google Chrome
- Mozilla Firefox
- Brave
- Safari
- Opera
- Microsoft Edge
- Internet Explorer (A partir de la versión 5.0)
Sistemas operativos compatibles
- Windows
- Linux
- MacOS
- Android
- iOs
Cómo convertir archivos y texto a UTF-8
Aunque existen varias páginas webs que ofrecen la posibilidad de convertir tus archivos a UTF-8, no todas son fiables y muchas de ellas están cargadas de publicidad incómoda. Es tan sencillo el proceso desde nuestros equipos que mi recomendación es que prescindas de ellas. Ahora veremos varios métodos a utilizar en función del sistema operativo que estés usando.
Convertir archivos a UTF-8 paso a paso
Convertir archivos en Windows
- Abres el archivo que deseas convertir a formato UTF-8 con el Bloc de notas
- Nos dirigimos a "Archivo > Guardar como"
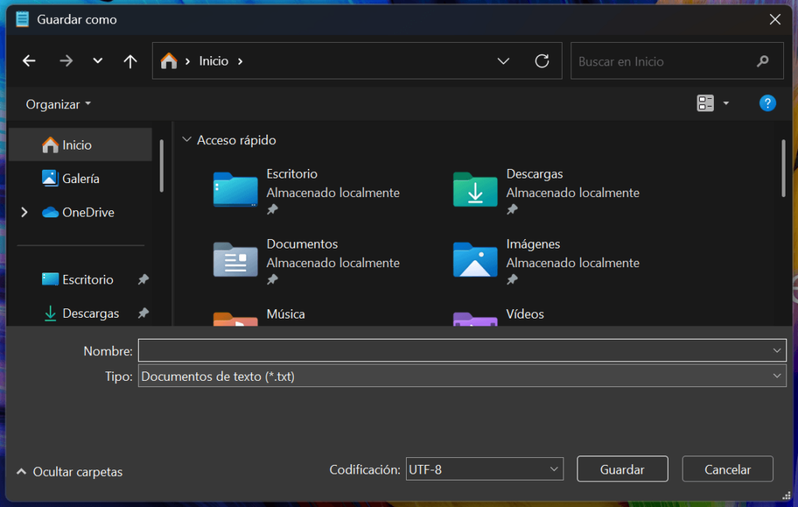
- En la ventana emergente marcamos "Codificación: UTF-8"
Convertir archivos en Mac
- Abres el archivo que deseas convertir a formato UTF-8 con TextEdit
- Nos dirigimos a "TextEdit > Preferencias > Abrir y guardar"
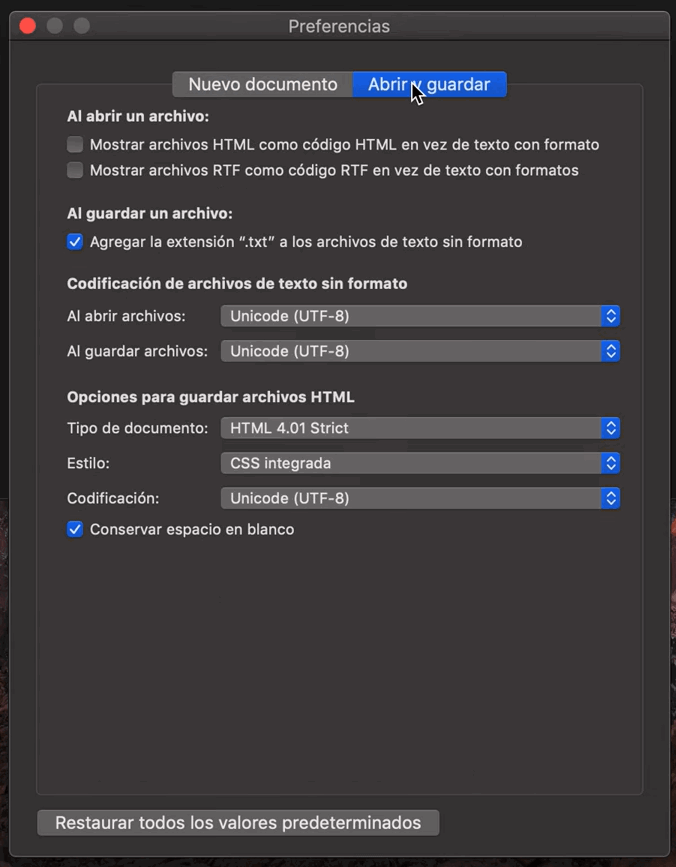
- En la sección "Al guardar archivos" seleccionamos "Unicode (UTF-8)"
Convertir archivos en Linux
- Abrimos la terminal
- Escribimos el siguiente comando sustituyendo la información.
iconv -f <codificaciónactual> -t UTF-8 <nombredelarchivoactual> -o <nombredelarchivonuevo>
- Nos dirigimos a la ubicación de la carpeta resultante y comprobamos.
¿Cómo saber si un archivo está en UTF-8?
Cualquier editor de texto, como Bloc de notas, TextEdit o Visual Studio Code, hoy en día suelen especificar la codificación de un archivo determinado cuando lo abres. Normalmente en la esquina inferior derecha, como puedes ver en la siguiente captura de ejemplo.

Caracteres extraños y errores de codificación
En alguna ocasión puedes encontrarte que el contenido no se visualiza correctamente. En la mayoría de casos suelen aparecer caracteres incorrectos y sin sentido como "�" en lugar de letras con acentos o caracteres concretos como "ñ" o "ç". Esto puede deberse a un conflicto de codificación o ajustes incorrectos en archivos, aplicaciones, etc. Por suerte, la mayor parte de estos problemas se pueden solucionar de forma muy sencilla, comprobando exactamente qué método de codificación se ha usado en los diferentes archivos, bases de datos, etc.
Por qué UTF-8 es el mejor estándar de codificación
Si has llegado hasta aquí, habrás comprobado que difícilmente podrás encontrarte, hoy en día, una codificación mejor que UTF-8. Funciona con cualquier caracter y por los principales navegadores y sistemas operativos. Es además muy usado en aplicaciones y software. Incluso usar otro método podría ocasionarte alguna incompatibilidad y errores de lectura con caracteres extraños.
Mi recomendación es que lo uses como norma general para todos tus archivos, de esa forma evitarás posibles problemas. Por supuesto, puedes consultar más información relacionada en nuestro blog y, como siempre, nos vemos en los comentarios ante cualquier duda o información que quieras añadir.




